Plankton Recognition
 Plankton Recognition
Plankton RecognitionTable of contents
Introduction
The goal of this challenge is to provide solid approaches to plankton image classification. The notebook is structured in such a way as to explore different tasks, including but not limited to data preparation and model selection.
In the first part, we will work directly with provided images after applying some preprocessing tasks. And then, we will work with the extracted features provided in the features_native file.
Image Data Preparation
The data set we will be using is composed of ~240K gray scale plankton images that were acquired in the bay of Villefranche and manually engineered features that were computed on each imaged object.
Data Exploration
First, let’s import the data set, have a look at the different available labels and the distribution of images among these classes.
This step is important in order to check wether our data set is imbalanced or not, and then choose the best evaluation metrics, e.g. if a data set is highly imbalanced, evaluating using the confusion matrix is more adapted than an overall accuracy.
img_files = utils.extract_zip_to_memory("/content/drive/My Drive/flowcam/imgs.zip")
np_ids, np_data = zip(*sorted(img_files.items()))
del img_files
np_ids, np_data = list(map(lambda s: int(''.join(filter(str.isdigit, s))), np_ids)), list(map(lambda img: np.array(Image.open(img)), np_data))
del np_ids
Since, we are dealing with a quiet big dataset of images, every time we will try to manage the memory by deleting unused variables.
meta_df = pd.read_csv("/content/drive/My Drive/flowcam/meta.csv")
sorted_level2 = meta_df.groupby('level2').size().sort_values(ascending=False)
sorted_level2.head()
level2
detritus 138439
feces 26936
Neoceratium 14014
nauplii (Crustacea) 9293
badfocus (artefact) 7848
dtype: int64
Class Distribution
The next plot shows how many images are available for each class in a descending order.
Note: A linear scale is used between $0$ and $100$ occurences in order to clearly visualize classes with few occurences. And a log scale is used for occurences above $100$ since values can reach $10^5$ for the detritus class.
fog, ax = plt.subplots(figsize=(16, 8))
y_thresh = 1e2
ax.set_yscale('symlog', linthreshy=y_thresh)
ax.hlines(y=y_thresh, xmin=0, xmax=39, linestyles='dashed')
ax.tick_params(axis='x', labelrotation=90)
sns.barplot(x=sorted_level2.index, y=sorted_level2.values, ax=ax)
<matplotlib.axes._subplots.AxesSubplot at 0x7fb4d22fce48>
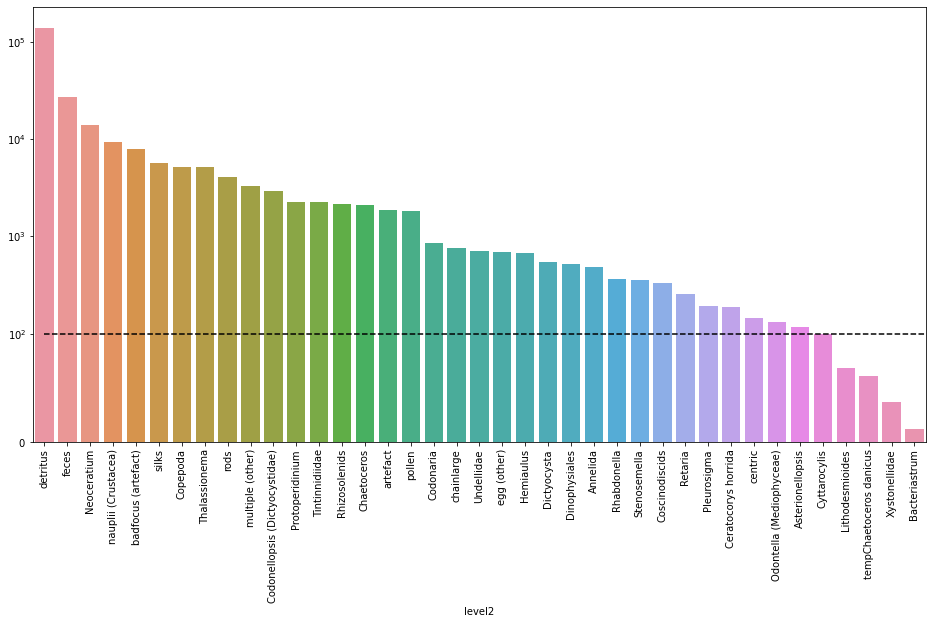
We can clearly see that we have an imbalanced data set. Working with such a distrubution will have a negative impact classifying images from under represented classes such as Bacteriastrum ($12$ samples), Xystonellidae ($37$ samples), etc. because the model won’t be able to lean much about those classes.
One solution for this problem is to use data augmentation. This approach will be discussed later.
Size Distribution
Now, we will focus on shapes of images. This is an important feature since we are working with an image data set because it will have a direct impact on the training process, e.g, performance and training time.
Let’s start by randomly displaying $30$ images picked from the data set.
utils.plot(data=np_data, seed=5)
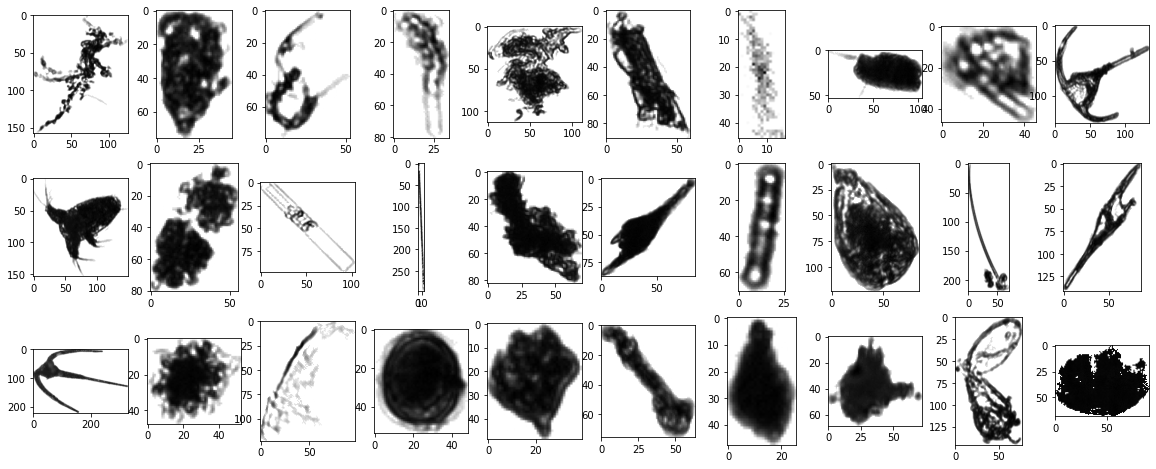
We can see that the images have different shapes. We are going to have a closer look on the distribusion of images' dimesions.
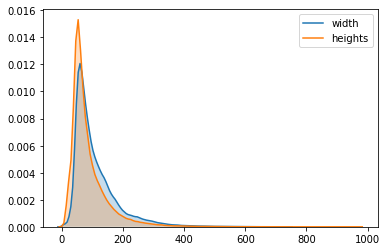
widths, heights = zip(*map(lambda x:x.shape, np_data))
sns.kdeplot(list(widths), label='width', shade=True)
sns.kdeplot(list(heights), label='heights', shade=True)
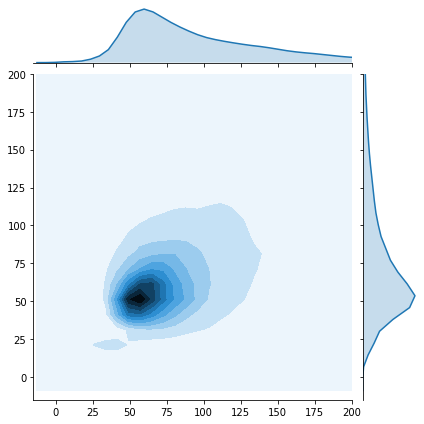
g2 = sns.jointplot(x=widths,
y=heights,
kind="kde",
xlim=(-15,200),
ylim=(-15,200))
del widths
del heights
The KDE plot is used to have a global view on the distribution of the shapes. We can see that the images have very different shapes that vary from few pixels up to about $1000$ pixels.
The joint plot was a good way to have a closer look on the distribusion of images' dimesions that are between $0$ and $200$ pixels. That helps us to choose the resizing value to be used.
We decided to rescale all images to 64x64x1 pixels for three main reasons:
- We will be using a convolutional neural network so all input samples should have the same size.
- As we can see in the joint plot, the shape distribution is concentrated around this value so we don’t have much processing to do.
- This value is not too small so we keep important information, and not too big so training process is much faster.
Note: Resizing the images is based on a a bicubic interpolation over 4x4 pixel neighborhood method already implemented in OpenCV.
Data Preprocessing
Now, let’s apply the reshaping function to all the images available in our data set. Then, we will show the same images after reshaping.
np_reshaped_data = list(map(lambda img : utils.reshape(img, 64), np_data))
del np_data
utils.plot(data=np_reshaped_data, seed=5)

np_reshaped_data = np.expand_dims(np.asarray(np_reshaped_data) / 255.0, axis=3)
Finally, we convert data to a NumPy array and scale all pixel intensities to the range [0, 1]. This will help speeding up gradient convergence during the training step.
A neural network cannot operate on label data directly. It requires all input variables and output variables to be numeric. That’s why we perform integer encoding for the data labels which transforms categorical data into numerical fields.
labelencoder = LabelEncoder()
meta_df["level2_label"] = labelencoder.fit_transform(meta_df["level2"].astype(str))
#np_y = meta_df.sort_values(by=['objid'])[['objid', 'level2_label']].astype(int).values[:,1]
meta_df=meta_df.sort_values('objid')
cat_targets = pd.factorize(meta_df['level2'])[0]+1 ## We want targets to start from 0
hot_targets = pd.get_dummies(cat_targets)
np_y=hot_targets
print("Input shape:", np_reshaped_data.shape)
print("Target shape:", np_y.shape)
Input shape: (243610, 64, 64, 1)
Target shape: (243610, 40)
Data Augmentation
One of the solutions to solve the problem of imblanced data distribution through the different classes is to perform data augmentation which consists of creating new data samples from the original ones by applying random perturbations to increase the size of the data set. Various transformation can be used such as rotation, translation, rescaling, flipping, etc.
We are going to use on-the-fly data augmentation using ImageDataGenerator class provided by Keras. That means this augmentation will be done at the training time.
Numerical Data Preparation
In this part, we will deal with numerical features extracted from images. So a whole set of preprocessing tasks well be discussed in the next few steps.
Let’s start by importing our data available in the features_native file, join meta data and features on objid and print an overview of the data set.
meta_df = pd.read_csv("/content/drive/My Drive/flowcam/meta.csv")
features_df = pd.read_csv("/content/drive/My Drive/flowcam/features_native.csv")
labelencoder = LabelEncoder()
meta_df["level2_num"] = labelencoder.fit_transform(meta_df["level2"].astype(str))
meta_df.columns
Index(['objid', 'projid', 'id', 'status', 'latitude', 'longitude', 'objdate',
'objtime', 'depth_min', 'depth_max', 'unique_name', 'lineage', 'level1',
'level2', 'level2_num'],
dtype='object')
data_df = features_df.join(meta_df[["objid", "level2_num"]].set_index('objid'), on='objid').drop(["objid"], axis=1)
data_df.describe()
| area | meanimagegrey | mean | stddev | min | perim. | width | height | major | minor | angle | circ. | feret | intden | median | skew | kurt | %area | area_exc | fractal | skelarea | slope | histcum1 | histcum2 | histcum3 | nb1 | nb2 | nb3 | symetrieh | symetriev | symetriehc | symetrievc | convperim | convarea | fcons | thickr | esd | elongation | range | meanpos | centroids | cv | sr | perimareaexc | feretareaexc | perimferet | perimmajor | circex | cdexc | kurt_mean | skew_mean | convperim_perim | convarea_area | symetrieh_area | symetriev_area | nb1_area | nb2_area | nb3_area | nb1_range | nb2_range | nb3_range | median_mean | median_mean_range | skeleton_area | level2_num | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 2.436100e+05 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.00000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 209182.000000 | 209182.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 209182.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 236756.000000 | 236756.000000 | 236756.000000 | 236756.000000 | 236756.000000 | 236756.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 243610.000000 | 236756.000000 | 243610.000000 |
| mean | 3954.559123 | 158.489675 | 218.064412 | 47.972455 | 101.442461 | 545.412294 | 86.939268 | 109.699889 | 146.871391 | 93.066144 | 58.594023 | 0.288874 | 129.299752 | 2.956125e+06 | 240.964603 | -1.426133 | 2.505907 | 94.10801 | 250.382858 | 1.049611 | 13209.067189 | 0.963900 | 165.681167 | 199.331932 | 234.226259 | 5.390583 | 5.633706 | 5.227195 | 1.737680 | 1.735016 | 5.155096 | 5.224933 | 13176.348832 | 12898.915816 | 163.106328 | 1.346968 | 99.874570 | 1.762178 | 153.557539 | -0.353172 | 0.587303 | 23.333286 | 30.423929 | 27.142845 | 8.214832 | 4.057089 | 3.524483 | 5.050091 | 0.039956 | 0.009251 | -0.005979 | 21.187097 | 80.242329 | 0.010013 | 0.009981 | 0.032841 | 0.034550 | 0.032731 | 0.034816 | 0.037358 | 0.035254 | 22.892997 | 0.148051 | 82.210980 | 27.891490 |
| std | 5478.161193 | 27.586551 | 25.088674 | 19.143144 | 31.879623 | 515.927925 | 62.118882 | 71.819207 | 86.093936 | 54.321102 | 42.897670 | 0.242218 | 80.530219 | 4.617139e+06 | 34.366794 | 1.268486 | 10.055730 | 8.60842 | 801.190148 | 0.077987 | 20146.988677 | 1.925124 | 56.143371 | 51.353393 | 32.497241 | 6.747436 | 8.012987 | 8.909747 | 0.772673 | 0.769537 | 5.844405 | 5.845856 | 20151.658603 | 20241.016241 | 159.922600 | 0.886610 | 17.413678 | 1.242256 | 31.879623 | 0.317733 | 3.907660 | 11.959699 | 9.562527 | 77.942987 | 25.223842 | 1.652132 | 1.508469 | 10.997803 | 0.708402 | 0.040341 | 0.005418 | 9.512411 | 129.959197 | 0.006027 | 0.006015 | 0.042003 | 0.051906 | 0.057964 | 0.042357 | 0.052351 | 0.058239 | 21.784279 | 0.126209 | 129.380889 | 7.226222 |
| min | 188.000000 | 0.000000 | 98.380000 | 1.113000 | 3.000000 | 60.380000 | 6.000000 | 9.000000 | 28.200000 | 15.800000 | 0.000000 | 0.001000 | 19.400000 | 1.262460e+05 | 67.000000 | -26.982000 | -1.964000 | 13.44000 | 0.000000 | 0.970000 | 555.000000 | 0.000000 | 0.000000 | 0.000000 | 67.000000 | 0.000000 | 0.000000 | 0.000000 | 1.144000 | 1.154000 | 0.000000 | 0.000000 | 508.000000 | 380.000000 | 0.000000 | 1.001000 | 0.000000 | 1.000000 | 7.000000 | -3.815789 | -45.000000 | 0.392157 | 1.834862 | 0.016034 | 0.004850 | 2.034682 | 1.622222 | 0.000000 | -12.000000 | -0.015267 | -0.106299 | 3.429603 | 2.228070 | 0.005747 | 0.005747 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -73.000000 | -0.376344 | 3.232558 | 0.000000 |
| 25% | 1646.000000 | 157.300000 | 202.770000 | 34.032000 | 83.000000 | 252.050000 | 50.000000 | 62.000000 | 86.900000 | 60.900000 | 0.000000 | 0.092000 | 73.400000 | 9.247488e+05 | 251.000000 | -2.047000 | -1.443000 | 92.19000 | 9.000000 | 1.013000 | 4444.000000 | 0.186000 | 118.000000 | 159.000000 | 233.000000 | 1.000000 | 1.000000 | 1.000000 | 1.435000 | 1.435000 | 2.000000 | 2.000000 | 4410.000000 | 4092.000000 | 24.663250 | 1.007000 | 98.000000 | 1.142857 | 141.000000 | -0.481481 | -1.000000 | 14.345992 | 22.929936 | 2.047657 | 0.472973 | 2.975207 | 2.500000 | 0.299199 | -0.020202 | -0.005102 | -0.008547 | 15.809914 | 25.071429 | 0.006061 | 0.006024 | 0.006410 | 0.006173 | 0.006024 | 0.009091 | 0.006623 | 0.006135 | 12.000000 | 0.083333 | 27.357576 | 30.000000 |
| 50% | 2435.000000 | 165.310000 | 222.460000 | 49.484000 | 97.000000 | 395.400000 | 67.000000 | 87.000000 | 120.700000 | 76.700000 | 90.000000 | 0.204000 | 104.800000 | 1.565890e+06 | 254.000000 | -1.198000 | -0.177000 | 97.64000 | 61.000000 | 1.020000 | 7189.000000 | 0.393000 | 156.000000 | 215.000000 | 249.000000 | 4.000000 | 3.000000 | 2.000000 | 1.490000 | 1.489000 | 3.000000 | 3.000000 | 7155.500000 | 6970.000000 | 118.620500 | 1.010000 | 104.000000 | 1.370968 | 158.000000 | -0.263566 | 0.000000 | 22.321429 | 31.818182 | 5.106039 | 1.215686 | 3.607143 | 3.106222 | 1.795196 | 0.000000 | 0.000000 | -0.004785 | 19.482353 | 42.975294 | 0.006536 | 0.006494 | 0.023952 | 0.018987 | 0.012739 | 0.024096 | 0.020979 | 0.014388 | 24.000000 | 0.156977 | 44.311377 | 30.000000 |
| 75% | 3953.000000 | 166.920000 | 237.860000 | 62.801000 | 114.000000 | 636.147500 | 104.000000 | 135.000000 | 178.300000 | 108.300000 | 90.000000 | 0.434000 | 159.300000 | 3.117444e+06 | 255.000000 | -0.555000 | 3.104000 | 99.67000 | 213.000000 | 1.025000 | 13824.000000 | 0.955000 | 219.000000 | 248.000000 | 252.000000 | 7.000000 | 7.000000 | 6.000000 | 1.686000 | 1.682000 | 6.000000 | 6.000000 | 13800.000000 | 13653.000000 | 263.097250 | 1.015000 | 106.000000 | 1.827160 | 172.000000 | -0.131034 | 4.000000 | 30.927835 | 38.690476 | 15.687500 | 4.139884 | 4.725352 | 4.125495 | 5.229442 | 0.035714 | 0.012712 | -0.004348 | 24.116485 | 84.197605 | 0.012121 | 0.012121 | 0.042169 | 0.042683 | 0.036364 | 0.045198 | 0.047619 | 0.040462 | 38.000000 | 0.237569 | 85.337580 | 30.000000 |
| max | 280773.000000 | 174.550000 | 254.560000 | 93.311000 | 248.000000 | 21714.830000 | 972.000000 | 739.000000 | 1105.800000 | 796.600000 | 90.000000 | 0.931000 | 1024.900000 | 1.425062e+08 | 255.000000 | 2.175000 | 919.038000 | 100.00000 | 123925.000000 | 1.465000 | 596160.000000 | 73.458000 | 253.000000 | 253.000000 | 255.000000 | 158.000000 | 225.000000 | 343.000000 | 21.911000 | 21.852000 | 138.000000 | 138.000000 | 596160.000000 | 596160.000000 | 1591.508000 | 11.965000 | 110.000000 | 31.000000 | 252.000000 | 0.000000 | 37.000000 | 70.731707 | 46.524064 | 2083.000000 | 755.000000 | 55.114213 | 57.447090 | 784.527697 | 20.000000 | 3.618110 | 0.020408 | 184.949971 | 5658.000000 | 1.000000 | 1.000000 | 3.000000 | 7.000000 | 7.000000 | 0.923977 | 1.618705 | 1.727941 | 84.000000 | 0.430769 | 5658.000000 | 39.000000 |
Normalization
Similarly to working with images, normalizing the numerical features is an important step that will help speeding up gradient convergence during the training step.
So at the beginning, let’s have a quick look at the distribution of means and std values for different features.
Note: we used a log scale for the y axis because values are scattered on a huge range.
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16,6))
sns.distplot(data_df.mean(axis=0), color="green", kde=True, bins=120, ax=ax1)
sns.distplot(data_df.std(axis=0), color="blue", kde=True, bins=120, ax=ax2)
ax1.set_title('Distribution of mean values')
ax2.set_title('Distribution of std values')
ax1.set_yscale('log')
ax2.set_yscale('log')
plt.show()
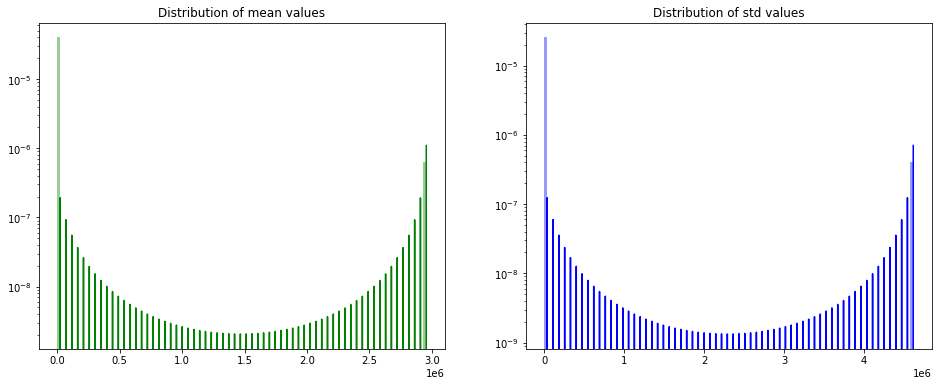
We can notice that the mean and std values have a wide distribution range (up to 1e6).
We can think about normalizing data by substructing the mean and dividing by the std value of each column. This normalizing step is very important in order to avoid any scaling problem (e.g distances between points won’t be dominated by features with high values) and also to speed up the training process (e.g. gradient descent will converge faster).
The new distribution of data values is shown is the next figure.
Note: we use the mean and the std of the training set to normalize in order to avoid introducing a bias in the data.
from sklearn.model_selection import train_test_split
X_train_df, _, _, _ = train_test_split(data_df.drop(['level2_num'], axis=1), data_df['level2_num'], test_size=0.2, random_state=42)
from scipy.stats import norm
features = X_train_df.columns
normalized_df = (X_train_df[features] - X_train_df[features].mean(axis=0)) / X_train_df[features].std(axis=0)
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16,6))
sns.distplot(data_df, kde=False, color="green", bins=500, ax=ax1)
sns.distplot(normalized_df, kde=False, color="green", bins=500, fit=norm, ax=ax2)
ax1.set_title('Distribution of data values')
ax2.set_title('Distribution of new data values')
ax1.set_yscale('log')
#ax2.set_yscale('log')
plt.xlim(-10,10)
plt.show()
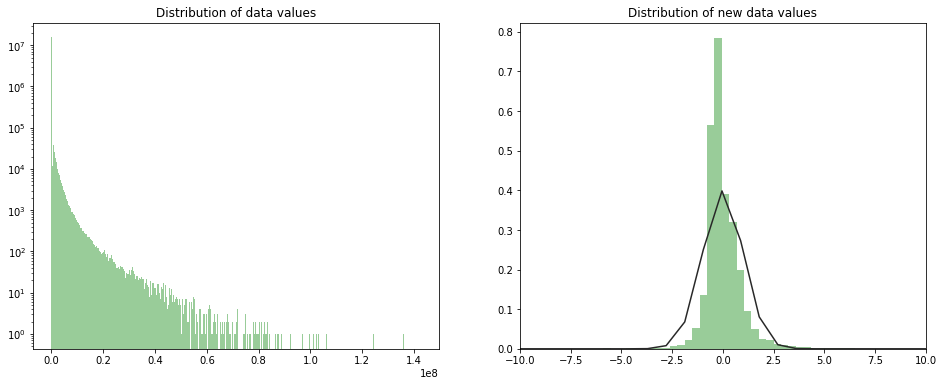
Correlation
As we can see we have so many features describing the data samples. Probably not all of these feature are importatnt to predict our target.
So now, we are going to keep only columns which are relevent to this problem.
So let’s have a quick look to the correlation between different features using the correlation matrix.
#correlation matrix
normalized_df['level2_num'] = data_df['level2_num']
corrmat = np.abs(normalized_df.corr())
mask = np.zeros_like(corrmat)
mask[np.triu_indices_from(mask)] = True
with sns.axes_style("white"):
f, ax = plt.subplots(figsize=(24, 20))
ax = sns.heatmap(corrmat, mask=mask, square=True, center=2)
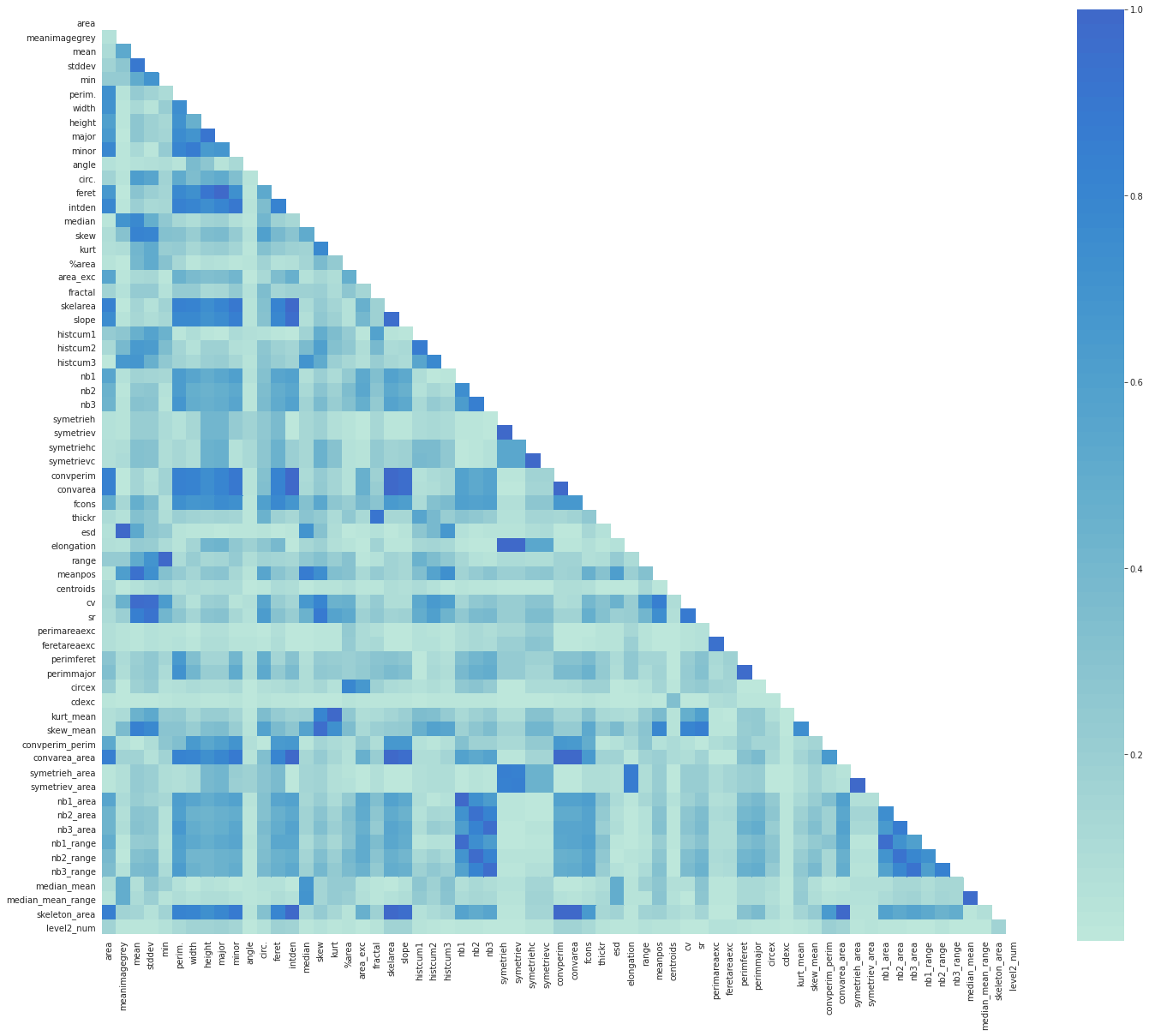
This heatmap gave us a great overview of our data as well as the relationship between different features.
We notice that there are many darkblue-colored squares: there are obvious correlations such as between nbX, nbX_range and nbX_area.
These columns give almost the same information, so we can get rid of extra ones.
# Select upper triangle of correlation matrix
upper = corrmat.where(np.triu(np.ones(corrmat.shape), k=1).astype(np.bool))
# Find index of feature columns with correlation greater than 0.95
to_drop = [column for column in upper.columns if any(upper[column] > 0.95)]
Here is the list of features to drop. As previously discussed it contains ‘nb1_area’, ‘nb2_area’, ‘nb3_area’, ‘nb1_range’, ‘nb2_range’ and ‘nb3_range’ which are correlated with nbX features.
to_drop
['feret',
'skelarea',
'slope',
'symetriev',
'symetrievc',
'convperim',
'convarea',
'esd',
'elongation',
'range',
'cv',
'perimmajor',
'kurt_mean',
'skew_mean',
'convarea_area',
'symetriev_area',
'nb1_area',
'nb2_area',
'nb3_area',
'nb1_range',
'nb2_range',
'nb3_range',
'median_mean_range',
'skeleton_area']
new_normalized_df = normalized_df.drop(to_drop, axis=1)
Missing Data
# Missing Data
total = new_normalized_df.isnull().sum().sort_values(ascending=False)
percent = (new_normalized_df.isnull().sum()/new_normalized_df.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
missing_data.head(5)
| Total | Percent | |
|---|---|---|
| cdexc | 27565 | 0.141440 |
| feretareaexc | 27565 | 0.141440 |
| perimareaexc | 27565 | 0.141440 |
| symetrieh_area | 5392 | 0.027667 |
| level2_num | 0 | 0.000000 |
We notice that 4 different columns have missing data. Since our data set is quiet big, we can choose to drop all samples that have at least one missing value and that won’t affect our results.
new_normalized_df = new_normalized_df.dropna()
Dataholders
We split our data using the same random_state previously used in order to get the same training and testing set. Then, we use One-Hot Encoder to get numerical labels and finally convert our data to numpy arrays.
Now, our data is ready to be used to train the model!
from sklearn.model_selection import train_test_split
X_train_df, X_test_df, y_train_df, y_test_df = train_test_split(new_normalized_df.drop(['level2_num'], axis=1), new_normalized_df['level2_num'], test_size=0.2, random_state=42)
from sklearn.preprocessing import OneHotEncoder
onehot_encoder = OneHotEncoder(sparse=False)
integer_encoded = y_train_df.values.reshape(len(y_train_df.values), 1)
y_train = onehot_encoder.fit_transform(integer_encoded)
onehot_encoder = OneHotEncoder(sparse=False)
integer_encoded = y_test_df.values.reshape(len(y_test_df.values), 1)
y_test = onehot_encoder.fit_transform(integer_encoded)
X_train, X_test = X_train_df.values, X_test_df.values
y_train, y_test = y_train_df.values, y_test_df.values
print("Features matrix shape:", X_train.shape)
print("Targets vector shape:", y_train.shape)
Features matrix shape: (129596, 40)
Targets vector shape: (129596,)
Models
Model for Images
meta_df = pd.read_csv("/content/drive/My Drive/flowacam/meta.csv")
cat_targets = pd.factorize(meta_df['level2'])[0]+1 ## We want targets to start from 0
hot_targets = pd.get_dummies(cat_targets)
hot_targets = hot_targets.set_index(meta_df['objid'].astype(int))
## define constants
IMG_SIZE = (64,64)
NUM_IMG = cat_targets.size
BATCH_SIZE = 512
EPOCHS=25
Data balancing
In the previous section we noticed that the data distribution with respect to classes is heavily skewed. If left unchanged our model would be more biased towards predicting classes with high cardinality.
If we were aiming sollely for accuracy this wouldn’t matter as the top 3 most occuring classes cover 70% of our data and our model would do great just by predicting these classes.
But our metric is the F1 score which gives equal importance to all of the classes. Thus we need to find a way to balance our data during training.
We considerer using some data augmentation techniques ONLY for the classes with low occurences, such as zooming, flipping … but we couldn’t find a time efficient way to do this.
Our workaround consisted of assigning weights to each class, such that the model is penalized more for missclassifying low cardinality classes.
weights = compute_class_weight('balanced', np.unique(cat_targets), cat_targets)
class_weights = dict(zip(np.unique(cat_targets), weights))
Our input consist of 64x64 grayscale images. We will be using Convolution Neural Networks to make our predictions.
Usually CNNs work with RGB images wich have 3 different channels. Inspired by this idea, our input image will have 3 channels as well. A channel for the normal grayscale image, one for the image passed through a thresholing filter. And one where we perform the morpholigical operation of opening. Opening should get rid of static around borders along with small artefacts whereas thresholding should make details clearer.
The intuition is that stacking these channels will give our model a clearer view of the object.
sub1 = plt.subplot(1,4,1)
plt.imshow(imgrey, cmap=cm.gray_r)
sub1.set_title("Original Image")
sub2 = plt.subplot(1,4,2)
plt.imshow(imthr, cmap=cm.gray_r)
sub2.set_title("Threshold Image")
sub3 = plt.subplot(1,4,3)
plt.imshow(imclosed, cmap=cm.gray_r)
sub3.set_title("Opened Image")
Text(0.5, 1.0, 'Opened Image')

Our dataset is too large to fit in memory.
To fix this problem we inherit the DirectoryIterator class.
This class allows us to fetch data from directory and feed it in real time to the model.
Note : We considered using the flow_from_directory function from Keras but this function required a specific structure of the training folder. It uses this structure to set the image labels.
To work our way around this we had to set the image attributes manually for each batch yielded by the generator.
We do this by overriding the get_batches_of_transformed_samples function.
We use the ImageDataGenerator class that allows us to perform data augmentation and preprocessing while reading from directory. And split our data into train and test set.
For our CNN architecture we chose an architecture similar to LeNET.
With 3 Convd + Maxpool layers and 3 Fully connected layers.
We use google colab with GPU’s for training.
Even with a relatively shallow network. Training time is of 4 minutes per epoch.
Note: Colab runtimes stop after approx 1h limiting us to 20 epochs for training.
LeNet = Sequential([
Conv2D(6, (2, 2), activation='relu', input_shape=(IMG_SIZE[0], IMG_SIZE[1], 3)),
MaxPooling2D(),
Conv2D(16, (2, 2),activation='relu'),
MaxPooling2D(),
Conv2D(16, (2, 2),activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(250, activation='relu'),
Dense(100, activation='relu'),
Dense(40,activation='softmax')
])
opt=tf.keras.optimizers.Adam()
LeNet.compile(optimizer=opt,
loss='categorical_crossentropy',
metrics=['accuracy',tfa.metrics.F1Score(num_classes=40,average='macro')])
#LeNet.summary()
Train The Model
import warnings
warnings.filterwarnings("ignore")
train_ds=train_ds.prefetch(tf.data.experimental.AUTOTUNE)
LeNet.fit(train_gen, epochs=1,class_weight=class_weights,steps_per_epoch=190000/BATCH_SIZE)
372/371 [==============================] - 225s 605ms/step - loss: 0.3235 - accuracy: 0.5294 - f1_score: 0.4571
<tensorflow.python.keras.callbacks.History at 0x7f39b6f42908>
After 30 epochs our model reaches an accuracy of 50% and an F1 score of 30% on test set.
It is worth mentioning that if we choose not to use use class weights our model can reach an accuracy of 80% and an F1 score of 25%.
loss, accuracy, F1_score = LeNet.evaluate_generator(test_gen)
print("Accuracy = ",accuracy, 'Loss = ',loss," Score = ",F1_score)
Accuracy = 0.5482328534126282 Loss = 1.5674445629119873 Score = 0.3294264078140259
Having an image classification task at hand. One could re use pre-trained models on big datasets such as cifar 10.
Such operation is called transfer learning where we take a pre-trained model ( A VGG 19 in our case) and remove the Fully connected layers on top that serve for classification.
The idea is that in order to perform classifications on datasets as large as Cifar100, VGG19 learns a latent image representation in the level of it’s intermediate layers. For example it can learn to find patters such wheels and other geometrical shapes.
Training : We freeze the first layers (which consist of convolutions) so that we dont have to retrain the whole model. Then we add some FC layers whose weights we’ll be training for our task.
NOTE : One epoch requires approx 11 minutes for no major change in accuracy. Training such a model may require a high number of epochs and we didn’t have the time to do so.
Model for Numerical Data
Since our data set is inbalanced, we use sample weighting which means increasing the contribution of an example to the loss function.
class_weights = list(class_weight.compute_class_weight('balanced',
np.unique(y_train),
y_train))
w_array = np.ones(y_train.shape[0], dtype = 'int')
for i, val in enumerate(y_train):
w_array[i] = class_weights[val-1]
xgb_model = xgb.XGBClassifier(objective="multi:softmax",
num_class=40,
random_state=42,
tree_method='gpu_hist',
gpu_id=0)
xgb_model.fit(X_train, y_train, sample_weight=w_array, verbose=True)
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, eval_metric='auc',
gamma=0, gpu_id=0, learning_rate=0.1, max_delta_step=0,
max_depth=3, min_child_weight=1, missing=None, n_estimators=100,
n_jobs=1, nthread=None, num_class=40, objective='multi:softprob',
random_state=42, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
seed=None, silent=None, subsample=1, tree_method='gpu_hist',
verbosity=1)
y_pred = xgb_model.predict(X_test)
The confusion matrix can allow the visualization of the performance of an algorithm. Since we have imbalanced data set, we visualized the log of the confusion matrix.
As we can see, even after using sample weights many samples are missclassified as class number 29 which is probably the class with highest number of sumples (about 1e5).
sns.heatmap(np.log(confusion_matrix(y_test, y_pred)+1))
<matplotlib.axes._subplots.AxesSubplot at 0x7fb318898be0>
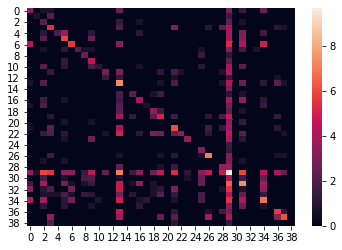
f1_score(y_test, y_pred, average='macro')
0.3323908881400761
Conclusion
In this challenge, we were tasked to classifiy plankton images.
This is usually a classical task. Our mission was particular because of the cardinality of the classes to predict (40) and the huge size of the dataset 240K. The data unbalance and the choice of the F1 metric made it more challenging.
As a conclusion we trained two models one CNN on image data and an Xgboost model on numerical features extracted from data.
Both yield similar F1 score of around 33%.
An interesting experience would be to have a model that combines features extracted via CNN and features extracted manually to make predictions.
Mokhles Bouzaien
Master of Science in Engineering Student
A self-motivated graduate student in Engineering at IMT Atlantique.